AI grades. Teachers stay in control.
An override workflow built around a real classroom — anomalies surface to the front of the queue, confident grades auto-publish, and every teacher decision is logged with the original AI verdict preserved.
Five stages from machine grade to teacher-signed score.
The AI grades, the system flags anything uncertain, the teacher decides — and every step of that decision is preserved.
AI grade
Every answer is scored against the key with math equivalence, choice rules, and partial credit applied uniformly across the class.
Anomaly flag
Low OCR confidence, large variance from the class, or unusual choice patterns surface the submission to the review queue — clean papers move on.
Teacher override
The teacher reviews the flagged answer, applies a one-tap override (or accepts the AI mark), and adds a short reason note for the audit log.
Final score
With teacher decisions applied, the per-question marks are finalised and rolled into the student's report — capped at each question's maximum.
Audit trail
Original AI verdict, prompt version, OCR confidence, every override and reason note — all preserved forever, queryable for later analysis.
Override anything. Keep the original AI verdict.
When a teacher overrides AI marks, Digiclove preserves the original — so you can later analyse where AI and teachers disagreed, and whether the AI is calibrating well over time.
- One-click override on per-question marks, with reason note
- Original AI marks & prompt version preserved on first override (forward-only)
- Teacher action log per submission — who changed what, when, why
- Bulk apply override patterns across the same question for the whole class

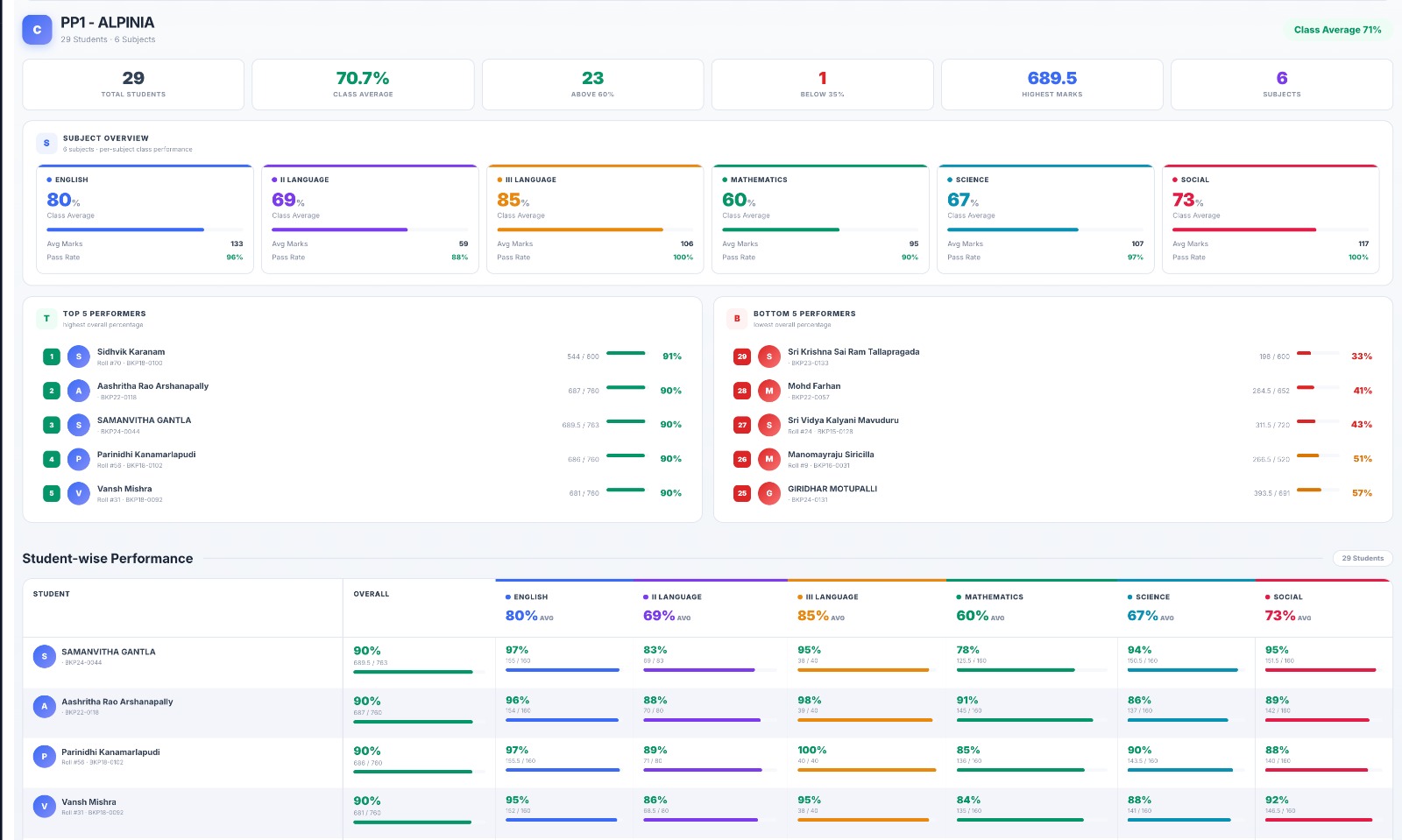
Every student, every subject, one screen.
The Class Student Detail Report gives teachers an instant read on how the whole class performed — ranked by overall percentage, with per-subject averages and top/bottom performer lists built in.
- KPI strip: total students, class average, above 60%, below 35%, highest marks, subject count
- Subject overview panel — per-subject class average, pass rate, and teacher name at a glance
- Top 5 and Bottom 5 performers ranked by overall percentage
- Full student table with per-subject marks and colour-coded percentage badges — click any student for a subject breakdown
- Filter by location, class, section, and one or more exam types
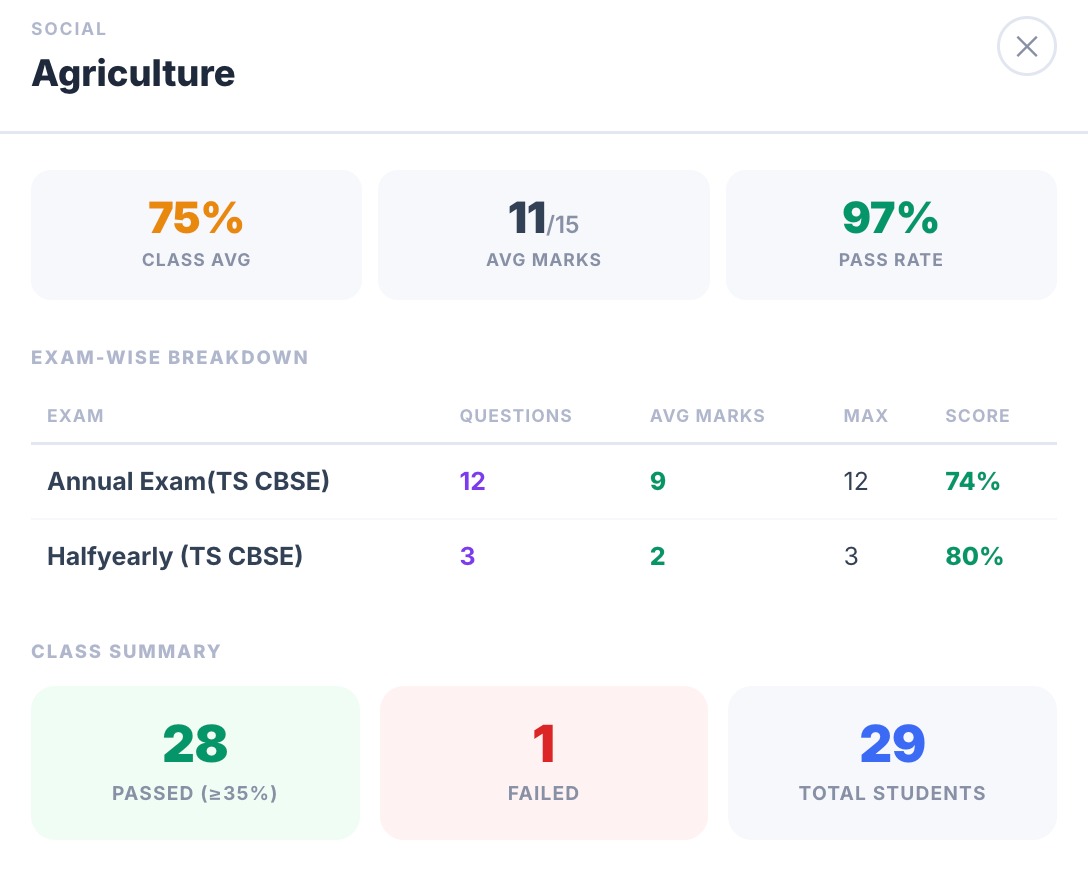
Click a subject. See every exam that touched it.
Drill into any subject from the class report and see the full picture — class average, average marks, pass rate, and a per-exam breakdown showing exactly how many questions appeared, what the class averaged, and the score percentage for each exam in the term.
- KPI tiles: class average %, average marks out of maximum, pass rate
- Exam-wise breakdown table — questions count, avg marks, max marks, and score % per exam
- Class summary: passed (≥35%), failed, and total students in one view
- Works across any number of exam types — annual, halfyearly, unit tests — in one panel
What happens after Teacher Review goes live.
Teacher review questions teachers ask first.
Which submissions are auto-approved versus surfaced for review?
When I override a mark, what gets recorded?
Can I apply the same override to the same question across the whole class?
What does the strictness setting actually change?
Will the AI learn from my overrides?
Run a parallel grading cycle. We'll compare.
Pick a paper your teachers already graded. We'll grade in parallel and show you exactly where AI agreed, where it didn't, and what teachers spent time on.